Applying Dimensionality Reduction in Collaborative Filtering Recommender Systems
 Dataset Link
Code Link
Dataset Link
Code Link
1. Problem statement:
- To predict top n movies for user using dimensionality reduction in collaborative filtering recommender systems by taking user_id and n as input.
- To optimize the dimensionality reduction models
2. Methodology:
Creating Ratings and Movies Matrix from Dataset:
Applying Singular Value Decomposition (SVD) on the data:
R (m*n) = U (m*m) S (m*n) VT (n*n)
- U is a left singular orthogonal matrix which represents the relationship between users and latent factors.
- S is a diagonal singular matrix which represents the strength of each latent factor.
- VT is the transpose of the right singular orthogonal matrix which represents the similarity between items and latent factors.
Applying Non-negative Matrix Factorization (NMF) on the data:
R (m*n) = W (m*k) H (k*n)
- The columns in W represent components, and H stores corresponding weights.
- The constraints are W ≥ 0 and H ≥ 0.
Training
Full data is used for training to give more accurate predictions.
Cross Validation
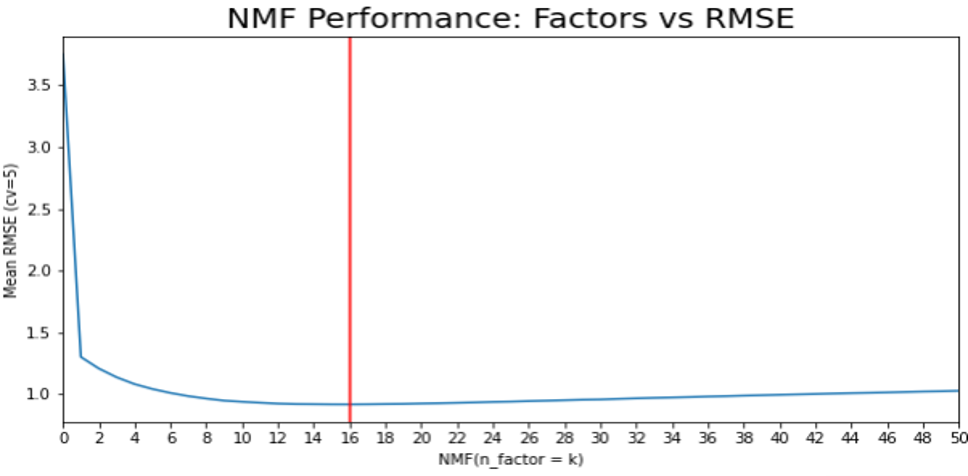
The training set is split into 5 folds. Root Mean Squared Error (RMSE) is used for analysis.
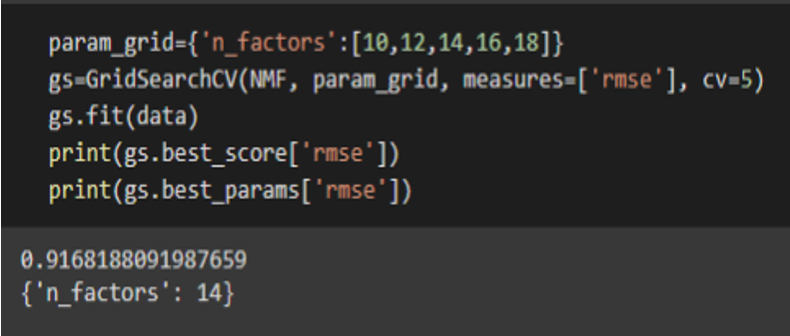
Grid Search
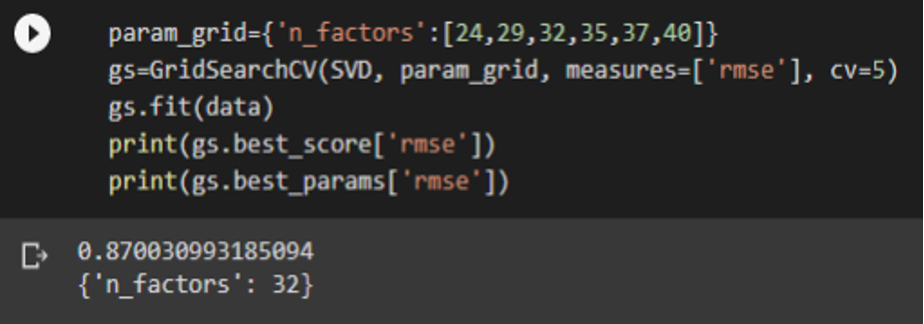
n_factors with the least RMSE are passed as parameters. The best n_factors is selected to avoid underfitting and overfitting.
Prediction
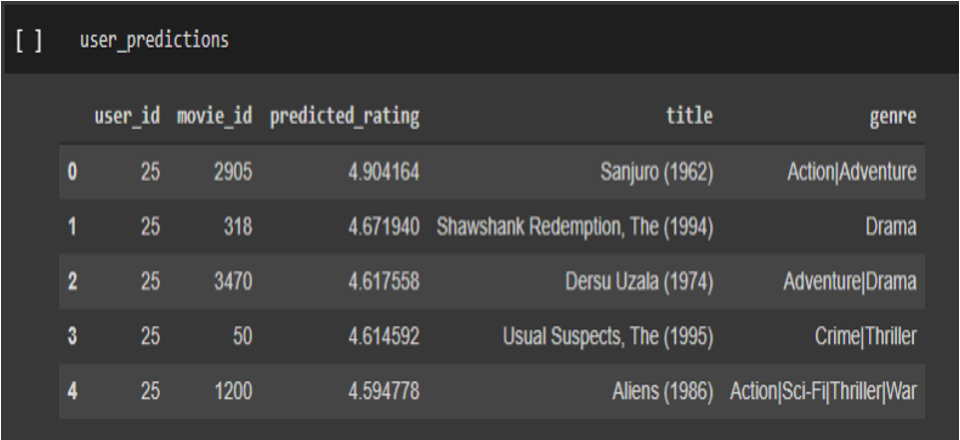
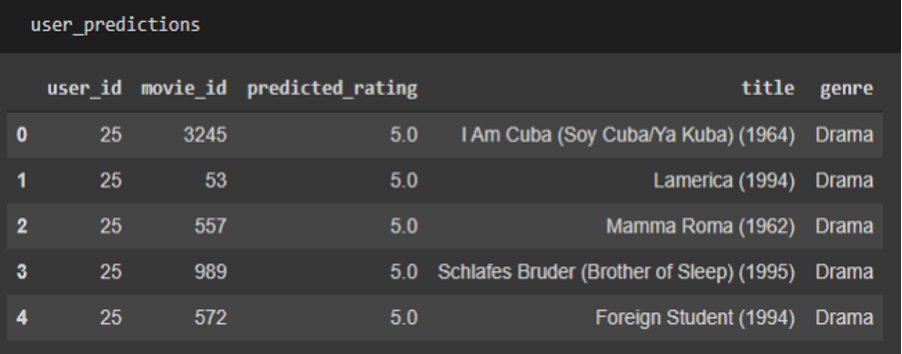
User_id and n are passed to the model to get the top n movies.
3. Results:
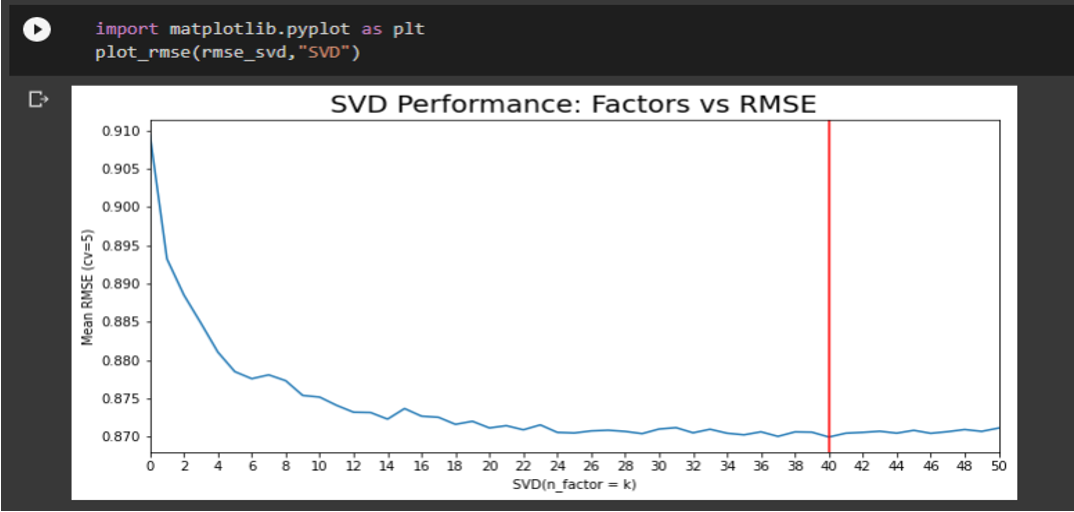
3.1 Factors vs RMSE (SVD):
3.2 Selecting best factor- Grid Search (SVD):
3.3 Top N movies prediction (SVD):
3.4 Factors vs RMSE (NMF):
3.5 Selecting best factor- Grid Search (NMF):
3.6 Top N movies prediction (NMF):
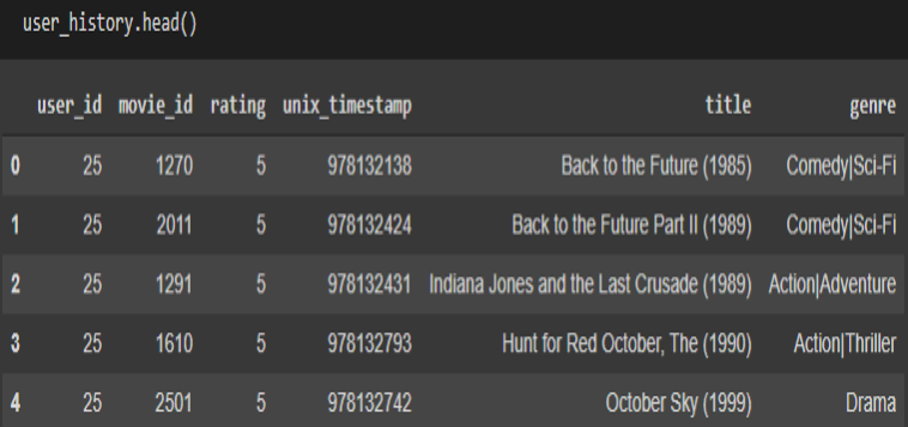
3.7 Users History:
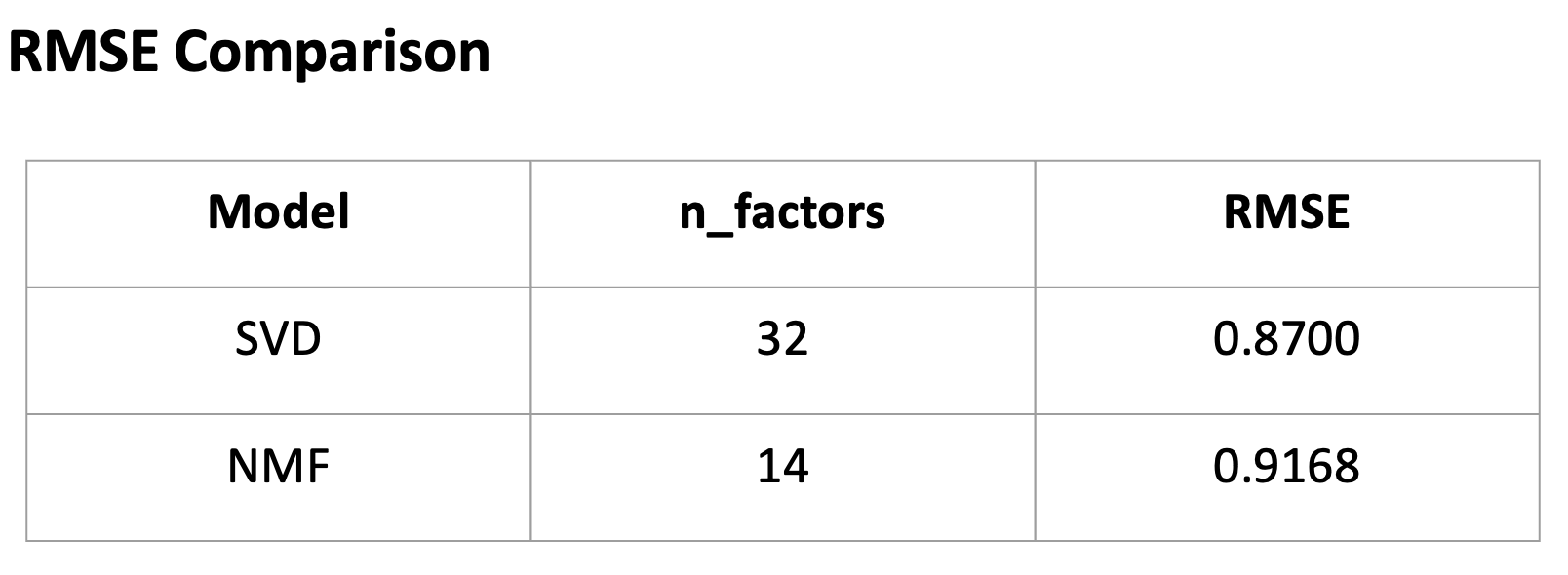
3.8 RMSE comparison
4. Conclusion
This project explored movie ratings data to understand and implement recommendation systems. Utilizing the MovieLens 1M dataset, which contains extensive movie ratings from users, the objective was to develop a system capable of suggesting movies to users based on their preferences.
Two different techniques were employed: Singular Value Decomposition (SVD) and Non-negative Matrix Factorization (NMF). These techniques allowed for the breakdown of the dataset into smaller components, enabling the identification of patterns and similarities between movies and users.
Following the training of the models on the entire dataset, their performance was evaluated using Root Mean Squared Error (RMSE) as a metric to ensure the accuracy of recommendations.
In conclusion, this project successfully constructed recommendation systems capable of providing movie suggestions to users based on their past preferences. Such systems hold potential utility for platforms like Netflix or Amazon Prime, aiding users in discovering new content aligned with their tastes.
Overall, this project sheds light on the functionality and application of recommendation systems using real-world datasets. Future endeavors could involve exploring more advanced techniques and integrating additional features to enhance recommendation accuracy.


